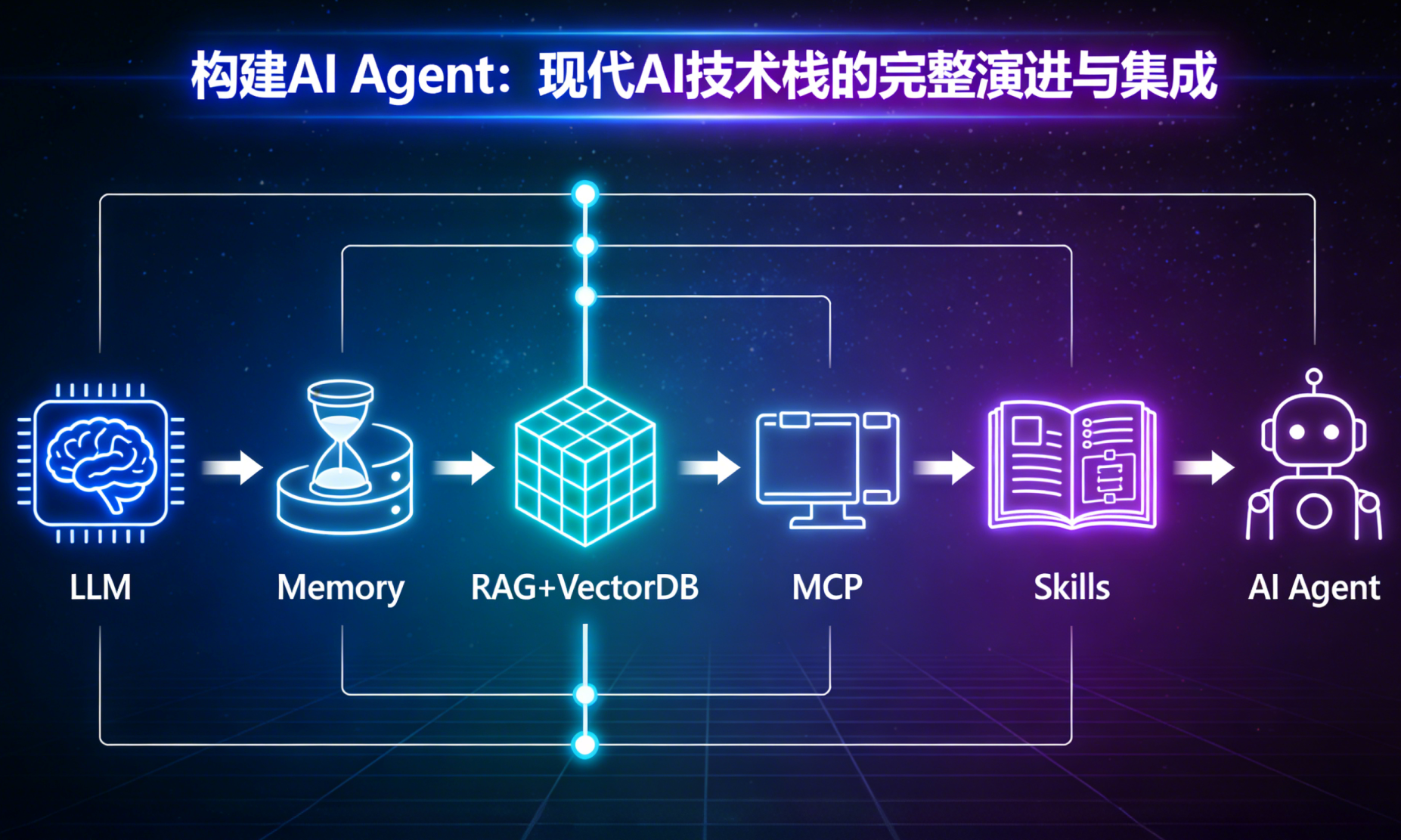
引言:现代AI技术栈的演进并非一蹴而就,而是一个系统性的“组装”过程。它始于一个强大的通用“大脑”,然后逐步为其添加记忆、知识、行动接口和专业技能,最终形成能够独立理解、规划并执行复杂任务的智能体(Agent)。本文将为你清晰拆解这一完整的技术栈演进路径。
一、全景图:AI Agent技术栈演进路径
下表概括了从“大脑”到“智能体”的六大关键层次,及其解决的核心问题:
二、基石与“大脑”:大型语言模型 (LLM)
LLM是构建一切AI应用的基石与通用“大脑”。它们基于Transformer架构,通过在海量文本数据上进行自监督学习(预测下一个词)来构建对语言、知识和逻辑的深刻理解。
工作原理:
- 注意力机制:让模型在处理每个词时都能“关注”到上下文中相关的所有词,这是理解长距离依赖关系的核心。
- 规模法则:模型参数规模(百亿到万亿)、训练数据量和计算资源的同步增长,带来了能力的“涌现”——即模型在达到一定规模后,会展现出在较小规模时不存在的新能力(如复杂推理、代码生成)。
- 微调与对齐:基础大模型(Base Model)通过指令微调(Instruction Tuning)和基于人类反馈的强化学习(RLHF)等对齐技术,被塑造成能遵循指令、有用且无害的助理模型(Chat Model)。
核心局限性(技术栈演进的驱动力):
- 金鱼记忆:标准Transformer的上下文长度有限,且每次推理都是静态前向传播,不保留状态。
- 知识“幻觉”与过时:知识固化为训练数据,可能生成看似合理但完全错误的内容,且无法获取训练截止
- 纸上谈兵:仅有“思考”(生成文本)能力,是一个封闭系统,缺乏感知和影响外部世界的能力。
国内主流大模型:阿里巴巴的通义千问、深度求索的DeepSeek、字节跳动的豆包、百度的文心一言、腾讯的腾讯元宝等。

国际主流大模型:OpenAI的ChatGPT、Google的Gemini、Anthropic的Claude、Meta的Llama、xAI的Grok等

三 、赋予“连续记忆”:记忆系统 (Memory)
记忆系统旨在为无状态的LLM注入连续的“状态”,是构建连贯、个性化智能体的关键。
技术实现分层:
- 短期/对话记忆:通常通过维护一个“对话缓冲区”来实现,将过往的问答对拼接在当前查询前,作为模型的输入上下文。这是最基本但也最受上下文窗口限制的方式。
- 长期/外部记忆:这是真正的工程重点。系统将历史交互中的重要信息(如用户偏好、事实摘要、任务状态)结构化后存储到外部数据库。
- 摘要与压缩:为了克服上下文长度限制,先进的记忆系统会对冗长的历史对话进行智能摘要,将关键信息压缩后存入长期记忆,以备未来检索。
挑战与前沿:如何判断哪些信息值得记忆?如何高效、准确地从海量记忆片段中检索出与当前场景最相关的信息?这引出了与RAG和向量数据库的紧密结合。
四、 连接“事实知识”:检索增强生成 (RAG)
RAG是一种将信息检索与文本生成相结合的范式,旨在用外部、可验证的知识源来“增强”并约束LLM的生成过程,从根本上缓解幻觉问题。
标准化工作流程:
- 索引(Indexing):预处理外部知识源(文档、数据库、API),将其分割成片段,并通过嵌入模型(Embedding Model)转换为向量,存入向量数据库。
- 检索(Retrieval):当用户查询到来时,先用同样的嵌入模型将其转换为查询向量,然后在向量库中查找语义最相似的K个文本片段。
- 增强(Augmentation):将检索到的相关片段(作为“证据”或“上下文”)与原始查询一起,构造成一个增强的提示(Prompt),提交给LLM。
- 生成(Generation):LLM基于包含证据的提示生成最终答案,通常会被要求引用来源。
核心价值:RAG实现了知识可更新(仅需更新向量库)、答案可溯源(提供引用)、成本可控(避免为注入新知识而重新训练大模型)。
五、知识的“检索引擎”:向量数据库 (Vector Database)
向量数据库是专门为高维向量(嵌入) 的存储、索引和检索而设计的数据库,它是RAG架构的性能中枢与事实记忆库。其核心价值在于,能将非结构化数据(文本、图像)转换为机器可理解的“语义向量”,并通过高效的相似性搜索,让AI系统拥有海量、精准的长期记忆。
核心技术机制:嵌入与检索的闭环
向量数据库的核心工作流程完全围绕 “嵌入模型” (Embedding Model) 展开,它是一个嵌入、存储、检索的闭环系统。
嵌入与插入:从文本到向量空间
- 过程:当一份文档需要存入知识库时,首先会通过一个嵌入模型进行处理。
- 作用:该模型将文档内容(或分块后的片段)转换成一个固定长度的、高维的数值向量。这个向量在数学空间中代表了该文本的语义。语义相近的文本,其向量在空间中的位置也彼此接近。
- 入库:生成的向量,连同其对应的原始文本片段和可选的元数据,作为一个“向量-文本对”被插入(Insert) 到向量数据库中。
索引与搜索:从问题到答案
- 查询转换:当用户提出一个问题,系统会使用同一个嵌入模型将该问题也转换为一个查询向量。
- 近似最近邻搜索:向量数据库的核心算法在此启动。它不会进行耗时的、精确的全量计算(比较查询向量与库中每一个向量的距离),而是利用预建的索引结构快速在向量空间中定位与查询向量最相邻的K个向量。
- 结果返回:系统召回这些相邻向量对应的原始文本片段及其元数据,将它们作为上下文提供给LLM,最终生成有据可依的答案。
六、 标准化“行动接口”:模型上下文协议 (MCP)
MCP是一套由Anthropic推动的开源协议,旨在标准化AI模型与外部工具、数据源之间的安全、声明式交互。
1.核心思想与组件:
- 解耦与抽象:MCP在AI应用(客户端)和工具/数据源(服务器)之间定义了一个清晰的边界。工具提供者只需按照MCP规范实现一个服务器,暴露其能力。
- 协议内容:
- 工具(Tools)声明:服务器向客户端宣告自己提供哪些工具(函数),包括名称、描述、参数模式(JSON Schema)。
- 资源(Resources)声明:服务器可以声明自己管理哪些静态或动态资源(如文件、数据库表),客户端可以读取其内容作为上下文。
- 安全上下文:所有交互都在明确定义的沙箱内进行,工具调用需要显式授权,提供了比过去“万能API密钥”更细粒度的控制。
- 传输层无关:MCP定义的是消息格式,可以通过stdio、HTTP、SSE等多种方式传输。
2.解决的问题与价值:
- 对开发者:无需为每个AI应用重复编写工具集成代码。只需一个支持MCP的AI应用(如Claude Desktop、Cursor),就能立即使用所有符合MCP的工具服务器。
- 对工具提供者:一次实现,多处可用。极大地扩展了工具的潜在用户群。
- 对生态:促进了工具生态的繁荣和标准化,降低了AI智能体获取“行动力”的门槛,是AI走向“操作系统化”的关键一步。
七、 封装“专业行动”:技能 (Skills)
技能代表了AI智能体能力的最高集成形式。它将利用LLM(大脑)、记忆、知识(RAG)和工具(MCP)来解决一个特定领域复杂问题的完整工作流,封装成一个可重复调用、甚至可共享的“黑盒”功能。
技能的本质:一个可执行的、目标导向的AI工作流。它通常包括:
- 目标理解与规划:解析用户指令,将其分解为一系列子任务或步骤。
- 多工具协调调用:根据规划,按顺序或条件调用多个底层工具(通过MCP)或子技能。
- 状态管理与错误处理:在工作流执行过程中维护状态,处理工具调用失败等异常。
- 结果综合与交付:将各步骤的中间结果综合整理,以用户期望的格式(文本、图表、文件)交付最终成果。
结语:从通用智力到专业能力之路
从LLM到Skills的演进,是一个从赋予“通用智力”,到补全“记忆”、“知识”、“感知与行动”短板,最终整合为“专业化能力”的系统工程。每一层都建立在下层之上,共同构成了现代AI智能体的完整技术栈。理解这个栈,是设计和构建下一代AI应用的基础