
引言:在探索人工智能的旅程中,我们常常惊叹于大语言模型(LLM)的博学多才,但也频频遭遇其令人挠头的局限——它可能会一本正经地谈论一个根本不存在的学术概念,或者对最近发生的新闻一无所知,以及无法接入私有知识。这正是当前大模型的局限所在:知识滞后、偶发“幻觉”、难以触及非公开信息。RAG(Retrieval-Augmented Generation,检索增强生成),作为一项关键的技术架构,它正像一个强大的“外接大脑”,有效地将大模型从一个“凭记忆聊天”的学者,转变为一个“实时查资料、有据可依、私有”的专业顾问。
一、技术本质:连接动态知识库与生成模型
RAG 的核心思想是在生成式模型的响应流程中,前置一个智能检索环节。该技术通过将信息检索系统与大语言模型深度集成,使模型在生成答案前能够从外部知识源中获取相关、最新的信息作为依据,从而将模型的参数化记忆与外部的非参数化知识库有机结合,实现了静态知识与动态需求的精准对接。
二、解决的核心问题:大模型的三个关键瓶颈
传统大语言模型在实际部署中面临三大挑战:
- 知识时效性边界:模型的知识截止于训练数据的时间点,无法自动获取后续信息。
- 事实性“幻觉”风险:模型可能基于统计模式生成看似合理但实际错误的内容。
- 专业知识可及性不足:无法访问未参与训练的私有化、专业化数据资源。
三、技术架构:构建可验证的知识增强系统
RAG 通过建立独立的外部知识检索模块来解决上述问题。该系统不修改模型内部参数,而是为其构建一个可按需查询的“外部记忆系统”,使生成过程从依赖内部记忆转变为基于证据的推理。这一架构确保了答案的准确性与可追溯性。
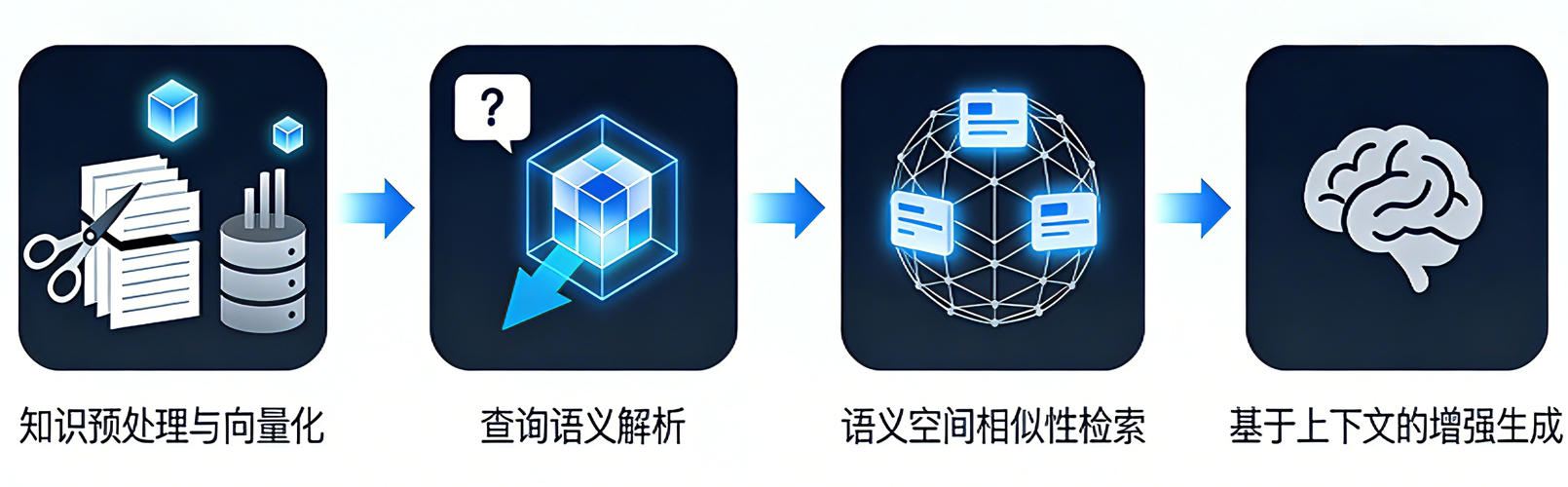
四、检索增强生成的实现实现流程:
- 知识预处理与向量化:原始文档被分割为语义完整的文本单元,通过嵌入模型转换为高维向量。这些向量代表了文本的语义特征,并存储于专门的向量数据库中,构建出机器可理解的语义索引系统。
- 查询语义解析:用户提问通过相同的嵌入模型被转化为查询向量,实现从自然语言到数学表示的转变,为语义层面的精准匹配奠定基础。
- 语义空间相似性检索:系统在向量空间内快速计算查询向量与文档向量的相似度,从知识库中召回最相关的文本片段作为生成答案的上下文依据。
- 基于上下文的增强生成:检索到的上下文与原始查询被结构化地组合为提示词,输入大语言模型。模型基于提供的证据进行信息整合与语言组织,生成既流畅又具备事实支撑的最终答案。
五、发展挑战与技术前沿
当前RAG系统的性能很大程度上取决于检索质量,错误或不完整的检索将直接影响生成结果的准确性。技术挑战主要集中在多跳推理检索、多源信息冲突解决、检索效率优化等方面。
未来发展趋势将聚焦于多模态检索增强、与推理智能体的深度融合,以及端到端检索生成联合优化等方向,进一步提升系统的智能化水平。
结语:准检索与智能生成共筑可靠AI未来
RAG技术代表了人工智能发展的重要方向。它通过巧妙的系统架构设计,将检索系统的精确性与生成模型的创造性有机结合,为构建可信、可靠、可追溯的人工智能应用提供了切实可行的技术路径。随着技术的不断成熟,检索增强生成正在推动人工智能从“表现智能”向“实用智能”的关键跨越,为各行各业智能化转型提供坚实的技术支撑。