引言:在计算机诞生的头几十年里,我们与机器交流的逻辑是极其“死板”的。传统的数据库(SQL)像是一个严苛的图书管理员,其核心逻辑是“非黑即白”的精确匹配。你输入“苹果”,它就在索引表里逐一比对。这种方式处理结构化数据时无往不利,但面对那些无法被轻易贴标签的情绪、意图、视觉特征——传统搜索就显得像个只有逻辑没有灵魂的机器。因为它无法处理“意义”,只能处理“字符”。向量数据库(Vector Database)的出现,本质上是人类试图将“感知”这一极其主观的行为,通过数学手段进行工程化量产的尝试。
一、 逻辑重构:从“箭头”到“特征打分表”
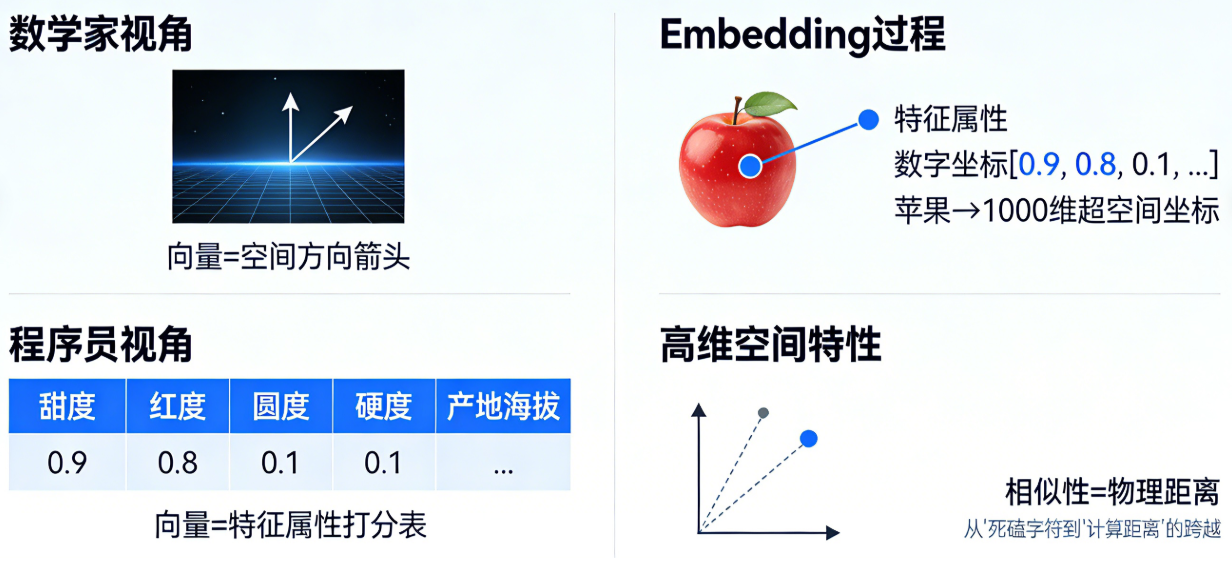
要理解向量数据库,首先要重构你对“向量”的认知。
在数学家眼里,向量是一个箭头,指向空间的某个方向;但在程序员眼里,向量其实是一*“特征属性的打分表”。
想象一下,如果我们用一千个维度去描述一个苹果,其中包括:甜度、红度、圆度、硬度、产地海拔……每一个特征都有一个从 0 到 1 的数字分值。最终,这个苹果就不再是一个单词,而是一串复杂的数字坐标(比如 $[0.9, 0.8, 0.1, ...]$),被投射在一个一千维的超空间里。
这个过程,就是 AI 领域常说的 Embedding(嵌入)。
它的深刻之处在于:它把模糊的、感性的“特征”,转换成了确定性的、理性的“空间坐标”。 在这个高维空间里,两个东西长得像不像、意思近不近,不再取决于文字是否重合,而是取决于它们在物理上的“距离”有多近。这种从“死磕字符”到“计算距离”的跨越,正是机器能够“理解”世界的数学基础。
二、 深度拆解:向量数据库里到底装了什么?
既然要把这种“理解”存起来,我们需要一个比 Excel 复杂得多的容器。一个成熟的向量数据库,其核心由以下四个维度构成:
- 特征向量(Vectors):数字化的灵魂
这是数据库的主体。它是一串高维浮点数。正如前文所说,它是事物的“特征指纹”。在数据库内部,这些数字不是被简单堆砌的,而是经过了数学压缩和量化,以便在极小的内存空间里容纳数以亿计的“含义”。
- 原始载体/负载(Payload):记忆的本体
光有坐标是不够的。当你根据坐标找到那个点时,数据库必须告诉你这个点到底代表了什么。它可能是那段话的原文、那张图片的 URL,或者是那个视频的片段。Payload 就是这些“原始信息”,让搜索结果变得可读、可用。
- 元数据(Metadata):逻辑的“围栏”
语义搜索虽然强大,但往往不够精准。在实际应用中,我们常需要配合传统过滤。比如:“寻找语义最接近‘人工智能’的文档,且发布日期必须在 2026 年之后(元数据过滤)”。元数据为模糊的语义海洋划定了一个明确的业务边界。
- 索引结构(Index):寻找的“地图”
这是向量数据库最昂贵的部分。在高维空间里,计算一个点与上亿个点之间的距离是极其缓慢的。为了快,它构建了特殊的导航地图(如 HNSW,层级导航小世界图)。它通过复杂的图论算法,让搜索在毫秒级时间内,从几亿个点中锁定离你最近的那几个“邻居”。

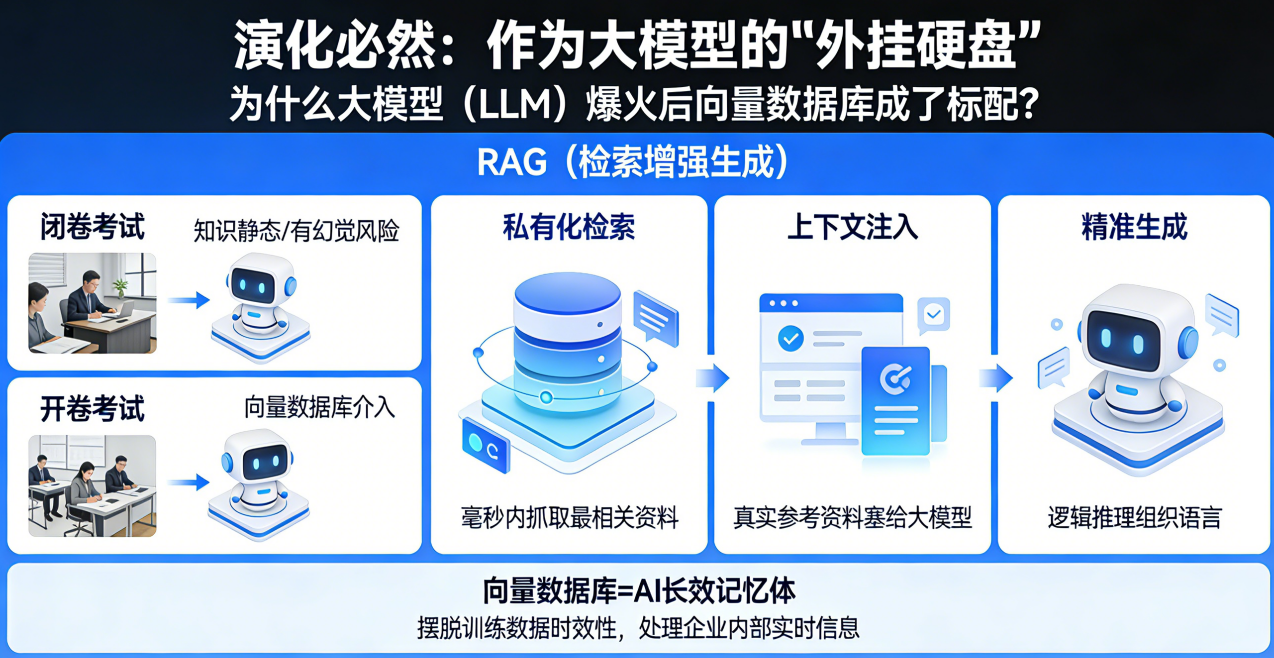
三、 演化必然:作为大模型的“外挂硬盘”
为什么大模型(LLM)爆火之后,向量数据库成了标配?这涉及到一个经典的应用架构:RAG(检索增强生成)。
大模型虽然博学,但它的知识是静态的,且有“幻觉”风险。它像是一个参加“闭卷考试”的天才,偶尔会记错公式。向量数据库介入后的 RAG 流程,把“闭卷考试”变成了“开卷考试”:
- 私有化检索: 当你问 AI 一个专业问题时,向量数据库先在毫秒内,从你的私有文档库中抓出最相关的资料。
- 上下文注入: 系统把这些真实的“参考资料”塞给大模型。
- 精准生成: 大模型不再拍脑袋瞎编,而是根据眼前的这几段资料,进行逻辑推理和组织语言。
向量数据库扮演了 AI 的“长效记忆体”。 它让 AI 摆脱了训练数据的时效性束缚,能够处理企业内部、实时更新的海量信息。
结语:理解的数字化,即是智能的平民化
向量数据库的兴起,标志着人类处理信息的逻辑发生了一次质变。
我们不再试图给世界打上死板的标签,而是试图捕捉事物之间微妙的联系。它不仅仅是一个存储工具,更是我们试图用数学去量化“理解”的一次成功尝试。
当万物皆可向量,世界在计算机眼中,便不再是一个个孤立的词条,而是一片连续的、可以被计算的意义海洋。而向量数据库,就是这片海洋里的导航仪。